
Join devRant
Do all the things like
++ or -- rants, post your own rants, comment on others' rants and build your customized dev avatar
Sign Up
Pipeless API

From the creators of devRant, Pipeless lets you power real-time personalized recommendations and activity feeds using a simple API
Learn More
-
Management : "How long you think it would take?"
Me : "now this is a rough estimate, but I think building the back-end and database alone could take 6-months minimum"
Management : "WHAT ARE YOU TALKING ABOUT? YOU ARE NOT SERIOUS"
me : "its a big proj..."
Management : "I thought it will be something like 10 days, already told the client it can be done"
me : "but we are not ready"
Management : "how are we not ready? we already have the virtual 3D shop, and we can use this ready-to-deploy eCommerce service as our data base "
... "you need to figure this out, this is not acceptable" he continued
* 2 Days Later -talking to my direct boss *
Boss : "since you don't know how to do it..."
me : "what ? I didn't say I can't do it, all I said it will take six months"
Boss : "yeah yeah, anyway there is this studio, a professional polish studio, we called them and they can do it, we will sign a contract with them, this will let you focus on the front-end. good?"
me : "well alright then"
Boss : "please write a doc, explaining everything needed from the backend"
-to me that was the end of it, took a long time to tell me they made the deal-
* 5 Months later *
- "Abdu, can you come here for a minute..."
- "yes boss?"
- "the document we asked you to do for the Polish studio, did you specify that we needed an integration with the API we are using for eCommerce?"
scared to death I answered : "why of course I did!"
I ran to my PC to check it out because I didn't know, I forgot because no one even comment on my doc. I check it out, and it was clearly explained... I got relaxed...
turns out they didn't even do what we asked them for. took them 5 months, and with no communication whatsoever. all their work was useless to us. complete dump waste.
----------------
never mentioned this until a year later... in a heat of moment when they were asking me to make an impossible task with no men and no time... I reminded them of this story... management didn't like it. but it was the truth. they didnt push this crazily this time13 -
You can believe or not but it’s just one of those stories. It’s long and crazy and it probably happened.
A few years ago I was interviewed by this big insurance company. They asked me on linkedin and were interested. They didn’t specify who they were so I didn’t specify who I am either.
After they revealed who they are I was just curious how they fuck they want to spend those billions of dollars they claimed in their press notes about this fucking digital transformation everyone is talking about. The numbers were big.
I got into 3 or 4 phone/skype interviews without technical questions and I was invited to see them by person.
I know that it would be funny because they didn’t asked me for CV so they didn’t know anything about me and I was just more curious how far I can get without revealing myself.
They canceled interview at midnight and I was in the middle of Louis de Funès comedies marathon so I didn’t sleep whole night. I assumed they would just reschedule but then they phoned me at 8 am if I can come because they made mistake.
So at first talk I was just interviewed by some manager I knowed after 5 minutes he would be shitty as fuck and demand stupid things in no time because he is not technical. He was trying to explain me that they got so great people and they do everything so fast.
From my experience speed and programming are not the things that match. ( for reference of my thought see three virtues of a GREAT programmer )
So I just pissed them off by asking what they would do with me when I finish this transformation thingy next year. ( Probably get rid off and fire at some point were my thoughts )
Then I got this technical interview on newest gold color MacBook pro - pair programming ( they were showing off how much money they have all the time ).
The person asked me to transform json and get some data in javascript .
Really that was the thing and I was so bored and tired that I just asked in what ES standard I can code.
The problem was despite he told me I can do anything and they are using newest standards ( yeah right ) the “for of” loop didn’t worked and he even didn’t know that syntax existed. So I explained him it’s the newest syntax pointing mozilla page and that he need to adjust his configuration. Because we didn’t have time for that I just did it using var an function by writing bunch of code.
When he was asking me if I want to write some tests probably because my code looked ugly as fuck ( I didn’t sleep for more then 24 hours at that point and wanted to live the building as fast as I can) I told I finished and there is no time for tests because it’s so simple and dumb task. The code worked.
After showing me how awesome their office is ( yeah please I work from home so I don’t care ) I got into the talk with VP of engineering and he was the only person who asked me where is my CV because he didn’t know what to talk about. I just laughed at him and told him that I got here just by talking how awesome I am so we can talk about whatever he wants.
After quick talk about 4 different problems where I introduced 4 different languages and bunch of libraries just because I can and I worked with those he was mine.
He told me about this awesome stack they’re building with kubernetes and micro services and the shitty future where they want to put IOT into peoples ass to sell them insurance and suddenly I got awake and started to want that job but behind that all awesomeness there was just .NET bridge with stack of mainframes running COBOL that they want to get rid off and move company to the cloud.
They needed mostly people who would dump code to different technology stack and get rid of old stack ( and probably those old people ) and I was bored again because I work more in r&d field where you sometimes need to think about something that don’t exist and be creative.
I asked him why it would take so much time so he explained me how they would do the transformation by consolidating bunch of companies and how much money they would make by probably firing people that don’t know about it to this day.
I didn’t met any person working permanently there but only consultants from corporations and people hired in some 3rd party company created by this mother company.
They didn’t responded with any decision after me wasting so much time and they asked me for interview for another position year after.
I just explained HR person how they treat people and I don’t want to work there for any money.
If You reached this point it is the end and if it was entertaining thank YOU I did my best.
Have a nice day.5 -
Unintentionally Hilarious joke at work yesterday.
We were doing some data analysis, and I had to dump some stuff into a table for my colleague. So I ran the script and went to the bathroom (no.2).
When I came back, they asked me if the dump is done. And I said without thinking: "I just went." 😂3 -
The solution for this one isn't nearly as amusing as the journey.
I was working for one of the largest retailers in NA as an architect. Said retailer had over a thousand big box stores, IT maintenance budget of $200M/year. The kind of place that just reeks of waste and mismanagement at every level.
They had installed a system to distribute training and instructional videos to every store, as well as recorded daily broadcasts to all store employees as a way of reducing management time spend with employees in the morning. This system had cost a cool 400M USD, not including labor and upgrades for round 1. Round 2 was another 100M to add a storage buffer to each store because they'd failed to account for the fact that their internet connections at the store and the outbound pipe from the DC wasn't capable of running the public facing e-commerce and streaming all the video data to every store in realtime. Typical massive enterprise clusterfuck.
Then security gets involved. Each device at stores had a different address on a private megawan. The stores didn't generally phone home, home phoned them as an access control measure; stores calling the DC was verboten. This presented an obvious problem for the video system because it needed to pull updates.
The brilliant Infosys resources had a bright idea to solve this problem:
- Treat each device IP as an access key for that device (avg 15 per store per store).
- Verify the request ip, then issue a redirect with ANOTHER ip unique to that device that the firewall would ingress only to the video subnet
- Do it all with the F5
A few months later, the networking team comes back and announces that after months of work and 10s of people years they can't implement the solution because iRules have a size limit and they would need more than 60,000 lines or 15,000 rules to implement it. Sad trombones all around.
Then, a wild DBA appears, steps up to the plate and says he can solve the problem with the power of ORACLE! Few months later he comes back with some absolutely batshit solution that stored the individual octets of an IPV4, multiple nested queries to the same table to emulate subnet masking through some temp table spanning voodoo. Time to complete: 2-4 minutes per request. He too eventually gives up the fight, sort of, in that backhanded way DBAs tend to do everything. I wish I would have paid more attention to that abortion because the rationale and its mechanics were just staggeringly rube goldberg and should have been documented for posterity.
So I catch wind of this sitting in a CAB meeting. I hear them talking about how there's "no way to solve this problem, it's too complex, we're going to need a lot more databases to handle this." I tune in and gather all it really needs to do, since the ingress firewall is handling the origin IP checks, is convert the request IP to video ingress IP, 302 and call it a day.
While they're all grandstanding and pontificating, I fire up visual studio and:
- write a method that encodes the incoming request IP into a single uint32
- write an http module that keeps an in-memory dictionary of uint32,string for the request, response, converts the request ip and 302s the call with blackhole support
- convert all the mappings in the spreadsheet attached to the meetings into a csv, dump to disk
- write a wpf application to allow for easily managing the IP database in the short term
- deploy the solution one of our stage boxes
- add a TODO to eventually move this to a database
All this took about 5 minutes. I interrupt their conversation to ask them to retarget their test to the port I exposed on the stage box. Then watch them stare in stunned silence as the crow grows cold.
According to a friend who still works there, that code is still running in production on a single node to this day. And still running on the same static file database.
#TheValueOfEngineers2 -
Testing hell.
I'm working on a ticket that touches a lot of areas of the codebase, and impacts everything that creates a ... really common kind of object.
This means changes throughout the codebase and lots of failing specs. Ofc sometimes the code needs changing, and sometimes the specs do. it's tedious.
What makes this incredibly challenging is that different specs fail depend on how i run them. If I use Jenkins, i'm currently at 160 failing tests. If I run the same specs from the terminal, Iget 132. If I run them from RubyMine... well, I can't run them all at once because RubyMine sucks, but I'm guessing it's around 90 failures based on spot-checking some of the files.
But seriously, how can I determine what "fixed" even means if the issues arbitrarily pass or fail in different environments? I don't even know how cli and rubymine *can* differ, if I'm being honest.
I asked my boss about this and he said he's never seen the issue in the ten years he's worked there. so now i'm doubly confused.
Update: I used a copy of his db (the same one Jenkins is using), and now rspec reports 137 failures from the terminal, and a similar ~90 (again, a guess) from rubymine based on more spot-checking. I am so confused. The db dump has the same structure, and rspec clears the actual data between tests, so wtf is even going on? Maybe the encoding differs? but the failing specs are mostly testing logic?
none of this makes any sense.
i'm so confused.
It feels like i'm being asked to build a machine when the laws of physics change with locality. I can make it work here just fine, but it misbehaves a little at my neighbor's house, and outright explodes at the testing ground.4 -
Cousins came over...
Me: just compiling some python code, opens up jupyter notebook to take a look at some data science code
Little Sis: *looks at jupnb dump on cmd*
Whoa are you Hacking?
Me: yeah. I got bored of whole Hacking command typing thing so I opened up my hacker console.
*print("hello world")*
Sis:wow!
Me: you know what, typing is too tiresome, I'll connect to it with my mind
*alt-tab*
*cmatrix -b*
*sits in yoga pose*
Little Sis: Screams at the top of her lungs and runs to aunt
"DAVE IS HACKING MATRIX"3 -
It's 17:55... Did much work that day since I came in earlier than usual, so I could leave in time and do some shopping with the girlfriend.
A colleague comes in to my room, a tad distressed. He had accidentally ran a fixture script on a production environment database (processing a shipload of records per minute), truncating all tables...
Using AWS RDS to rollback the transaction log takes up about 20m. I had to do that about 5 times to estimate the date and time of when the fixture script ran... Since there was no clear point in time...
Finally I get to the best state of the data I could get. I log in remotely run some queries. All is well again... With minor losses in data.
I try to download a dump using pg_dump and apparently my version is mismatched with the server. I add the latest version to aptitudes source list of postgres repo and I am ready to remove and purge the current postgres client and extensions...
sudo apt-get remove post*
Are you sure? (Y/n) *presses enter and enters into a world of pain*
Apparently a lot of system critical applications start with post... T_T4 -
My god the wall looks really punchable right now. Let me tell you why.
So I’m working on a data mining project, and I’m trying to get data from google trends. Unfortunately, there have been a lot of roadblocks for what should have been an easy task.
First it won’t give a raw search volume, only relative “interest”.
Fortunately it lets me compare search terms, which would work for my needs however it will only let me compare a few at a time. I need to compare 300.
So my solution is simple: compare all the terms relative to one term. Simple enough, but it would be time consuming so I figured I’d write a program to get the data.
But then I learned that they don’t have an official api. There’s a node module for this very thing based on a python module that reverse engineers the api endpoints. I thought as long as it works I’d use it.
It does work... But then I discovered that google heavily rate limits the endpoints.
So... I figured I’d build a system to route the requests through different tor nodes to get around the rate limit. Good solution right? Well like a slap to the face, after spending way to much time getting requests through tor working, I discovered that THEY FUCKING BLOCKED TOR IPS.
So I gave up, and resigned to wait 5 hours for my program to get the data... 1 comparison at a time... 60s interval between requests. They, of course, don’t tell you the rate limit threshold, so this is more or less a guess (I verified that 30s interval was too short and another person using the module suggested 60s).
Remember when I said the discovery that the blocked tor came like a slap to the face? This came as a sledge hammer to the face: for some reason my program didn’t dump the data at the end. I waited 5 fucking hours to get nothing.
I am so mad right now. I am so fucking mad.4 -
Everyone and their dog is making a game, so why can't I?
1. open world (check)
2. taking inspiration from metro and fallout (check)
3. on a map roughly the size of the u.s. (check)
So I thought what I'd do is pretend to be one of those deaf mutes. While also pretending to be a programmer. Sometimes you make believe
so hard that it comes true apparently.
For the main map I thought I'd automate laying down the base map before hand tweaking it. It's been a bit of a slog. Roughly 1 pixel per mile. (okay, 1973 by 1067). The u.s. is 3.1 million miles, this would work out to 2.1 million miles instead. Eh.
Wrote the script to filter out all the ocean pixels, based on the elevation map, and output the difference. Still had to edit around the shoreline but it sped things up a lot. Just attached the elevation map, because the actual one is an ugly cluster of death magenta to represent the ocean.
Consequence of filtering is, the shoreline is messy and not entirely representative of the u.s.
The preprocessing step also added a lot of in-land 'lakes' that don't exist in some areas, like death valley. Already expected that.
But the plus side is I now have map layers for both elevation and ecology biomes. Aligning them close enough so that the heightmap wasn't displaced, and didn't cut off the shoreline in the ecology layer (at export), was a royal pain, and as super finicky. But thankfully thats done.
Next step is to go through the ecology map, copy each key color, and write down the biome id, courtesy of the 2017 ecoregions project.
From there, I write down the primary landscape features (water, plants, trees, terrain roughness, etc), anything easy to convey.
Main thing I'm interested in is tree types, because those, as tiles, convey a lot more information about the hex terrain than anything else.
Once the biomes are marked, and the tree types are written, the next step is to assign a tile to each tree type, and each density level of mountains (flat, hills, mountains, snowcapped peaks, etc).
The reference ids, colors, and numbers on the map will simplify the process.
After that, I'll write an exporter with python, and dump to csv or another format.
Next steps are laying out the instances in the level editor, that'll act as the tiles in question.
Theres a few naive approaches:
Spawn all the relevant instances at startup, and load the corresponding tiles.
Or setup chunks of instances, enough to cover the camera, and a buffer surrounding the camera. As the camera moves, reconfigure the instances to match the streamed in tile data.
Instances here make sense, because if theres any simulation going on (and I'd like there to be), they can detect in event code, when they are in the invisible buffer around the camera but not yet visible, and be activated by the camera, or deactive themselves after leaving the camera and buffer's area.
The alternative is to let a global controller stream the data in, as a series of tile IDs, corresponding to the various tile sprites, and code global interaction like tile picking into a single event, which seems unwieldy and not at all manageable. I can see it turning into a giant switch case already.
So instances it is.
Actually, if I do 16^2 pixel chunks, it only works out to 124x68 chunks in all. A few thousand, mostly inactive chunks is pretty trivial, and simplifies spawning and serializing/deserializing.
All of this doesn't account for
* putting lakes back in that aren't present
* lots of islands and parts of shores that would typically have bays and parts that jut out, need reworked.
* great lakes need refinement and corrections
* elevation key map too blocky. Need a higher resolution one while reducing color count
This can be solved by introducing some noise into the elevations, varying say, within one standard div.
* mountains will still require refinement to individual state geography. Thats for later on
* shoreline is too smooth, and needs to be less straight-line and less blocky. less corners.
* rivers need added, not just large ones but smaller ones too
* available tree assets need to be matched, as best and fully as possible, to types of trees represented in biome data, so that even if I don't have an exact match, I can still place *something* thats native or looks close enough to what you would expect in a given biome.
Ponderosa pines vs white pines for example.
This also doesn't account for 1. major and minor roads, 2. artificial and natural attractions, 3. other major features people in any given state are familiar with. 4. named places, 5. infrastructure, 6. cities and buildings and towns.
Also I'm pretty sure I cut off part of florida.
Woops, sorry everglades.
Guess I'll just make it a death-zone from nuclear fallout.
Take that gators!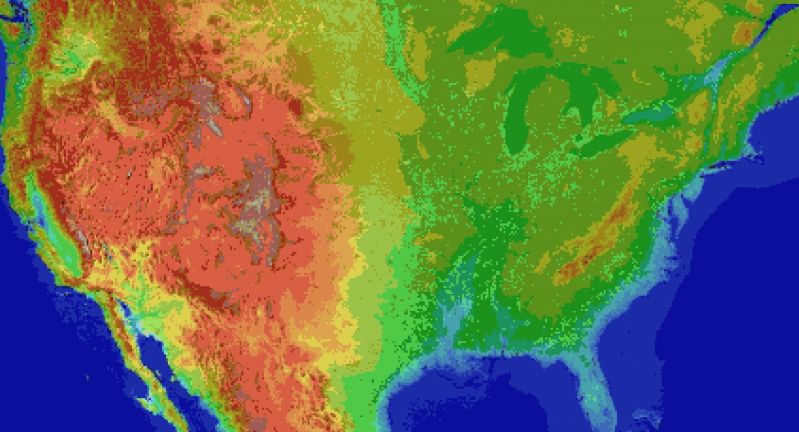 5
5 -
List of shit my superior said and wrote in the project:
1. Prefer to write "pure" SQL statement rather than ORM to handle basic CRUD ops.
2. Mixing frontend and backend data transformation.
3. Dump validation, data transformation, DB update in one fucking single function.
4. Calculate the datetime manually instead of using library like momentjs or Carbon.
5. No version control until I requested it. Even with vcs, I still have to fucking FTP into the staging and upload file one by one because they don't use SSH (wtf you tell me you don't know basic unix command?)
6. Don't care about efficiency, just loop through thousands of record for every columns in the table. An O(n) ops becomes O(n * m)
7. 6MB for loading a fucking webpage are you kidding me?
Now you telling me you want to make it into AJAX so it'll response faster? #kthxbye2 -
We need an open-source alternative to stack overflow. They have fucking monopolizing pieces of ratshit admins there and lame ass bots.
I HAD A FUCKING 450 REP :/ and now i have "reached my question limit"
I mean its okay of you want to keep stackoverflow clean , but straight out rejecting the new queries should be against your god damn principles, if those mofos have any!
If it is so easy to downvote and delete a question for the mods, why can't they create a trash site called dump.stackoverflow.com ? whenever a question is not following their stupid guidelines , downvote it to oblivion. After a certain limit, that question goes to dump space where it will be automatically removed after 30 days. Atleast give us 30 fucking days to gather attention of audience !
And how does a question defines someone's character that you downright ban the person from asking new questions? Is there a phd that we should be doing in our mother's womb to get qualified as legitimate question author?
"No questions are stupid" is what we usually hear in our school/college life. And that's a stretch, i agree. Some questions are definitely stupid. But "Your questions are so stupid we are removing you from the site" is the worst possible way to deal with a question asker.
Bloody assholes.
Now, can anyone tell me that if am passing a parcelable list of objects in an intent before starting a new activity, how can i retrieve it in the new activity without getting any kotlin warnings?
The compiler is saying that the data coming via intent is that of list<Type!> aka list of platform type, so how to deal with this warning?15 -
>uni project
>6 people in group
>3 devs (including me)
I am in charge of electronics and software to control it as well as the application that will use them.
2 other "devs" in charge of a simple website.
Literally, static pages, a login/registration, and a dump of data when users are logged in.
Took on writing the api for the data as well, since I didn't fully trust the other 2.
Finished api, soldered all electronics, 3d printed models.
Check on the website.
Ugly af, badly written html and css.
No function working yet.
Project is due next week Thursday.
Guess who's not having a weekend and gonna be pulling 2 all nighters2 -
Oh god where do I start!?
In my current role I've had horrific experiences with management and higher ups.
The first time I knew it would be a problem: I was on a Java project that was due to go live within the month. The devs and PM on the project were all due to move on at the end. I was sitting next to the PM, and overheard him saying "we'll implement [important key feature] in hypercare"... I blew my top at him, then had my managers come and see if I was OK.
That particular project overran with me and the permanent devs having to implement the core features of the app for 6mo after everyone else had left.
I've had to be the bearer of bad news a lot.
I work now and then with the CTO, my worst with her:
We had implemented a prototype for the CEO of a sister company, he was chuffed with it. She said something like "why is it not on brand" - there was no brand, so I winged it and used a common design pattern that the CEO had suggested he would like with the sister company's colours and logo. The CTO said something like "the problem is we have wilful amateurs designing..." wilful amateurs. Having worked in web design since I was 12 I'm better than a wilful amateur, that one cut deep.
I've had loads with PMs recently, they basically go:
PM: we need this obscure set up.
Me & team: why not use common sense set up.
PM: I don't care, just do obscure set up.
The most recent was they wanted £250k infrastructure for something that was being done on an AWS TC2.small.
Also recently, and in another direction:
PM: we want this mobile app deploying to our internal MDM.
Us: we don't know what the hell it is, what is it!?
PM: it's [megacorp]'s survey filler app that adds survey results into their core cloud platform
Us: fair enough, we don't like writing form fillers, let us have a look at it.
*queue MITM plain text login, private company data being stored in plain text at /sdcard/ on android.
Us: really sorry guys, this is in no way secure.
Pm: *in a huff now because I took a dump on his doorstep*
I'll think of more when I can. -
I really don't understand this particular Government Department's IT Unit. They have a system and network to maintain except:
- They don't have a DBA
- They don't have a dedicated Network Engineer or Security Staff
- Zero documentation on all of the systems that they are taking care of (its all in each assigned particular staff's brain they said)
- Unsure and untested way of restoring a backup into a system
- Server passwords are too simple and only one person was holding this whole time and its to an Administrator account. No individual user account.
- System was developed by an in-house developer who is now retired and left very little documentation on its usage but nothing on how its setup.
But, the system has been up and operational for the past 20 years and no major issues whatsoever with the users using it. I mean its a super simple system setup from the looks of it.
1 App Server connected to 1 DB Server, to serve 20-30 users. But it contains millions of records (2GB worth of data dump). I'm trying to swing to them to get me on a part time work to fix these gaps.
God save them for another 20 years.3 -
>Raspberry Pi on 16GB SD card
>Plugs in 2 flash drives for space, one 8GB and one 32GB
>8GB is allocated entirely for swap
>32GB is separated into 3 partitions and /etc/fstab edited to mount them on /home, /opt and /usr
>Moves files to the proper partitions on stick
>Kernel panic on boot before keyboard is enabled, kernel panic data taller than screen
>No R/W FS for kernel to dump to
fuck my life4 -
<sanityCheck> //asking for a friend
Some clever b*****ds wrecked a section of our production mysql db. To fix it I need to rollback the affected records 2 weeks - around 50/300 tables are affected, the other data must remain intact.
Currently my plan is to take a 2 week old dump and cherry pick the data I need from it, then combine it with a dump of the db in it's current state, drop the db and recreate it.
I know this approach will work - but it's risky, a pain in the ass and dealing with 300mb text files is tedious so since I only need to start in around 8 hours I figured It wouldn't hurt to post my approach and see if anyone thinks my plan is borderline retarded.
If you have any advice .etc that will make my life easier I would greatly appreciate it.
So in your opinion...
- is there a better/safer way?
- do you know of any db dump merge tools?
- have a recommended (linux) text editor for large text files?
- have you made any personal mistakes/fuck ups in the past you think I should avoid?
- am I just being a moron and overthinking this?
- if I am being a moron - In your humble opinion has the time come for me to give up all hope and pursue my dream of becoming a professional couch surfer?
</sanityCheck>
Note: Alternatively, if your just pissed that my rant is asking for a solution instead of simply trashing the people that created my situation and your secretly wishing it was on SO where it belongs so you can moderate/edit/downvote/mark the shit out it, feel welcome to troll me in the comments (getting dev advice just doesn't feel reliable without a troll - you matter to me). Afterwards If your panties are still in a bunch I'll post it on SO and dm a link to you to personally moderate - my days already fucked and I wouldn't want to ruin yours too.4 -
So we are migrating between different hosts so I write a nice script to move two pieces of encrypted data between the two, one over ssh, the other over https to two separate end points. One boss says can’t do that as it is insecure because they come from the same script!
Another boss objected that I wrote a script to dump databases in bash rather than like his in PHP even all his PHP does is run the same bash commands, I just took out the middleman and made it faster.
#baddayintheoffice #anyonelookingforaseniordev1 -
Other dev in group chat: we need to stop syncing so much data from prod to uat because it's crashing the uat db...
Me thinking: no really... U just realized it's not a good idea to dump most of the prod db into uat every week?
¯\_(ツ)_/¯4 -
How do you restore partial data from a mysql backup? Don't worry, nothing is wrong, I'm just thinking about how would I restore something if shit hits the fan.
Our current strategy for database backups is to just run mysqldump during the night, using a cronjob (feel freue to suggest a better way ;))
1) Restoring the full db: just read that sql file into the mysql command.
2) Restoring just one (or some) tables: open the file in an IDE, just select the lines you're after, copy them to a new file, read that one (possible issues: let's say we have a table B to which entries of table A are related and we just want to restore table A. We can't nuke table B too, as also table C is refering to it, so we have to do some orphant removal in B afterwards)
3) Restoring selected entries in specific tables: setup a new db, read the full backup in there, dump these entries to a new file and read that into the real db
How do you so it? Any better aproaches/tools?8 -
I am supposed to make a module that does sftp to third parties. Users put in their credentials and we connect and dump files on their servers. It seems like a terrible idea. We don’t administer those computers or define anything about their security. We don’t know if they are entering third party credentials or handling data according to our TOS. Can’t we just send them a presigned link by email on a schedule or something?2
-
Ok, this question is related to mysql and php.,
Let me state the current situation
I have a db, say "gd".
That db has several tables all with same columns.(i.e same fields for different manufacturers such as product name, cost , stock etc.)
Now i want to know how many tables have the product 'a' in them and what's the cost of 'a' in each of those table.(tables are generated dynamically so I'll never now how many tables are there, well ofcourse i can refer information schema, but just wanted to highlight this fact). So is there a way to achieve this?.. excluding "dump the whole data and then search it" solution.
Plz help, .. sorry for my bad English, .9 -
I hate when programming books have shit code examples.
Just came across these, in a single example app in a Go book:
- inconsistent casing of names
- ignoring go doc conventions about how comments should look like
- failing to provide comments beyond captain obvious level ones
- some essential functionality delegated to a "utils" file, and they should not be there (the whole file should not exist in such a small project. If you already dump your code into a "utils" here, what will you do in a large project?)
- arbitrary project structure. Why are some things dumped in package main, while others are separated out?
- why is db connection string hardcoded, yet the IP and port for the app to listen on is configurable from a json file?
- why does the data access code contain random functions that format dates for templates? If anything, these should really be in "utils".
- failing to use gofmt
These are just at a first glance. Seriously man, wft!
I wanted to check what topics could be useful from the book, but I guess this one is a stinker. It's just a shame that beginners will work through stuff like this and think this is the way it should be done.3 -
God, these people...
Little backstory. I'm making an training application and we have a MySQL database set up where some elements of the training are configured. This is so learning experts can easily change some aspects of the training without programmer's help.
Meanwhile, I'm also in the middle of a server migration, because our current server is running a lot of deprecated software and is in dire need of replacement.
This is going pretty slowly, though, because of other, high-priority, work that keeps being shoved my way.
Now, someone accidentally deletes a bunch of data from one of the schemas. No big deal in my book, the training is still in development and we have nightly backups of the database.
So I shoot a support ticket to the hosting provider and ask them to restore a specific schema, telling them to restore the image to some other machine and dump the tables in an MySQL file so I can restore it that way.
I also told them to get the backup of the OLD server, not the NEW one we're still migrating to.
About an hour later, I get a message that they dumped the schema's files in a Temp folder on the D drive. So I RDP to the server to check and... The files aren't there. Just before writing a response asking where the file is, I remembered the server I was migrating to and checked that server, and there were the files.
I had already migrated part of our databases and was testing compatibility before I moved to something else.
The hosting provider just dumped the files of the wrong server, despite me telling them exactly which server to use.
This is not the first time this hosting provider has let me down...
I'm really considering jumping to another if they keep doing this... -
The PM is trying to dump the responsibility of change management onto me
What the absolute fuck im your developer and you want me to spend my time filling in data on spreadsheet? Everytime I update an environment I send out emails by fucking hand already because ya'll to cheap for change management software, fill your own damn spreadsheet. You know, do management, your job?
For fucks sakes2 -
The pain of creating a data pipeline in AWS to dump all your DynamoDB tables into S3 is something I don't want anyone else to go through..Why don't you have a copy button..😭😭
-
The biggest mistake my colleague done is -
update query for admin_reports table without where clause in mysql in production db. Right after that no admin reports. More than 1000 rows affected.
Glad we luckily we have some data in staging machine.. I don't know Why TF our devops team not taking backup. Hope they will from now.
Nom I'm using python to dump the data from staging and save it local file and then export to production.
#HisLifeSucks
#HeartBeatsFast -
Well thanks a lot for the clarification of WHY I cannot sync my work (Office 365) mail using the mail client in Windows 10!
It's not that it's wrong; it's (probably) very much correct.
It's not that it's not precise; I don't think it could be anymore precise than a data dump like that.
It's not that trying to help me solve the problems; I'm sure it is.
But now that I have all the (debug) info about the security policies in place it would be great if it would show what violated which policy and maybe even what they mean and how to fix it?
The most concrete to go by is the error code, and judging by a google that has meant "your mail has problems" for at least three years...
...not even a single link was found to the (only) page detailing content, possible values, and dependencies between policies.
-
Okay, so, I have a functional snort agent instance, and it's spewing out alerts in it's "brilliant" unified2 log format.
I'm able to dump the log contents using the "u2spewfoo" utility (wtf even is that name lol... Unified2... something foo) but... It gives me... data. With no actual hint as to *what* rule made it log this. What is it that it found?
All I see are IDs and numbers and timings and stuff... How do I get this
(Event)
sensor id: 0 event id: 5540 event second: 1621329398 event microsecond: 388969
sig id: 366 gen id: 1 revision: 7 classification: 29
priority: 3 ip source: *src-ip* ip destination: *my-ip*
src port: 8 dest port: 0 protocol: 1 impact_flag: 0 blocked: 0
mpls label: 0 vland id: 0 policy id: 0
into information like "SYN flood from src-ip to destination-ip" -
I know it's not made to be resilient in any way, only fast, as fast as possible, but man, the memcache_tool script just made my life a million times easier by facilitating a complete data transfer between two memcache instances, allowing for a rolling update without any session data loss!
...One day... I hope it can be migrated to redis... But for now... Thanks lord for the dump command and the wrapper script <3





























Top Tags
Weekly Rant
View